
Introduction
So I’ve decided to stop using snapchat. I was once a heavy snapper who couldn’t help but send everyone 5 minute updates on how my day is going but it’s time for a change. I don’t find myself using it as much anymore and to be honest I’m not quite happy with the privacy implications of using it. So before I go about deleting my account I would like to backup all my memories from snapchat as I don’t have backups elsewhere.
Let’s find the data
The easy way to this is to obviously just download all the memories to my phone from the app and transfer them to my computer but that seems like a hassle and I don’t have it installed on my new phone anyways. Many jurisdictions in Europe and some in the US now require that companies disclose to you any information they have pertaining to your account, so I looked up snapchat’s to see what they had to offer.
Sure enough they have a download link at https://accounts.snapchat.com/accounts/downloadmydata
I figured I this was going to be a tomorrow project at this point seeing as it was 7 at night and it can take up to 24 hours, but before I could even navigate to my email client I got the notification that my download was ready.
Data investigation
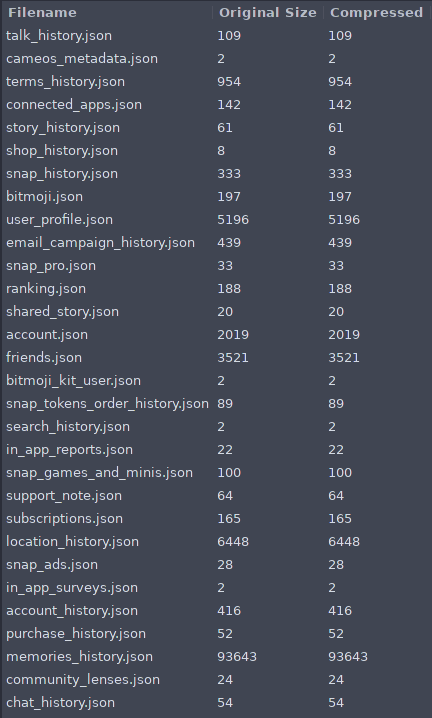
Sure enough there’s lots of data in the downloaded zip, but to be honest I thought there would be more (I sure know there is with google). Probably the worst is the fact that they know in location_history.json how many times I went to dairy queen this summer D:
So there’s lots of stuff to look at and I’ll probably dive into it further some other time but let’s stick to the task at hand. The file memories_history.json is probably what we’re looking for.
Having a look at the file it has a bunch of entries of this format:
1
2
3
4
5
{
"Date": "2020-08-14 16:22:59 UTC",
"Media Type": "PHOTO",
"Download Link": "https://app.snapchat.com/dmd/memories?uid=<GIANT_UID_FOR_MY_ACCOUNT>"
}
Well this doesn’t look so bad, each item contains a ‘Media Type’ attribute that contains either ‘PHOTO’ or ‘VIDEO’. I’ll just loop through the objects in a python script and download the “Download Link” attributes. Let me shove that link in my browser just to verify it’s one of my files.
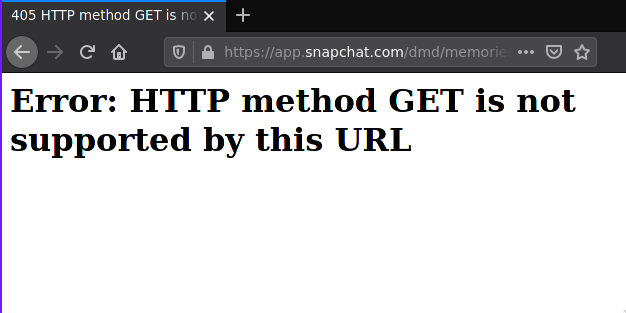
Uhh, okay. Well it can’t always be easy. I guess this means the page is looking for a different type of request. Going to go out on a limb and say if it’s not GET, it’s probably going to be POST (sorry PATCH, PUT and DELETE). To verify this we can once again use one of my favorite command line utilities curl.

Well that request worked, and it’s response contains another URL that points to an AWS server. Sure enough if I click that link one of my images appears. Awesome so we’ve found our data
Designing our python script
Okay so our script is going to have to do a few things in a specific order for this to work:
- The script will need to read in and parse our json file
- In a loop the script will need to get the real url by making a post request to the proxy url
- Then our script can download the response from the AWS server into it’s proper file format
I’ll start by writing my python boilerplate and getting the file read in and the json parsed.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#!/usr/bin/env python
import argparse
import json
import sys
import requests
import datetime
from os.path import exists
parser = argparse.ArgumentParser()
parser.add_argument("jsonfile", help="json file to parse")
args = parser.parse_args()
if not exists(args.jsonfile):
print("Given file does not exist")
sys.exit(1)
jsonObj = None
with open(args.jsonfile, "r") as handle:
jsonObj = handle.read()
if not jsonObj:
print("Failed to read given json file")
sys.exit(1)
obj = json.loads(jsonObj)
print(obj)
Not too bad, now we have the json parsed in our script, we just have to work on the downloading. I’ll make a function downloadItem that gets passed one of our video/photo objects and downloads the link into a file. In this instance I’m going to try and be extra protective and do lots of checks to avoid overwriting any existing data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
def generateSerializedDT(dt):
curDt = datetime.datetime.strptime(dt, '%Y-%m-%d %H:%M:%S %Z')
serialized = str(curDt.year) + "-" + str(curDt.month).zfill(2) + "-" + str(curDt.day).zfill(2) + "_" + str(curDt.hour).zfill(2) + "_" + str(curDt.minute).zfill(2) + "_" + str(curDt.second).zfill(2) + "_UTC"
return serialized
def downloadItem(item):
resp = requests.post(item['Download Link'])
if resp.status_code != 200:
print("PHANTOM LINK STATUS: " + str(resp.status_code))
return False
if not resp.text:
print("PHANTOM LINK EMPTY")
return False
imgDownload = requests.get(resp.text)
if imgDownload.status_code != 200:
print("IMG DOWNLOAD STATUS: " + str(imgDownload.status_code))
return False
if len(imgDownload.content) < 1:
print("IMG DOWNLOAD CONTENT EMPTY")
return False
downloadName = generateSerializedDT(item['Date'])
ext = ".mp4"
if item['Media Type'] == "PHOTO":
ext = ".jpg"
downloadName = downloadName + ext
if exists(downloadName):
print(downloadName + " EXISTS, IT SHOULDN'T, FATAL!")
return False
with open(newName, "w+b") as handle:
handle.write(imgDownload.content)
return True
Alright so I went a little overboard. It’s not super pretty but I only plan on using this script once so it will work.
Using a main loop that iterates through each photo/video object I call my downloadItem function. If it receives false then the download is treated as a failure and the whole script stops. Pretty safe I think? I also created another function generateSerializedDT that just takes the datetime and makes it into an acceptable filename.
Let’s give it a go!

So far so good…. oh wait..
Unexpected Problems
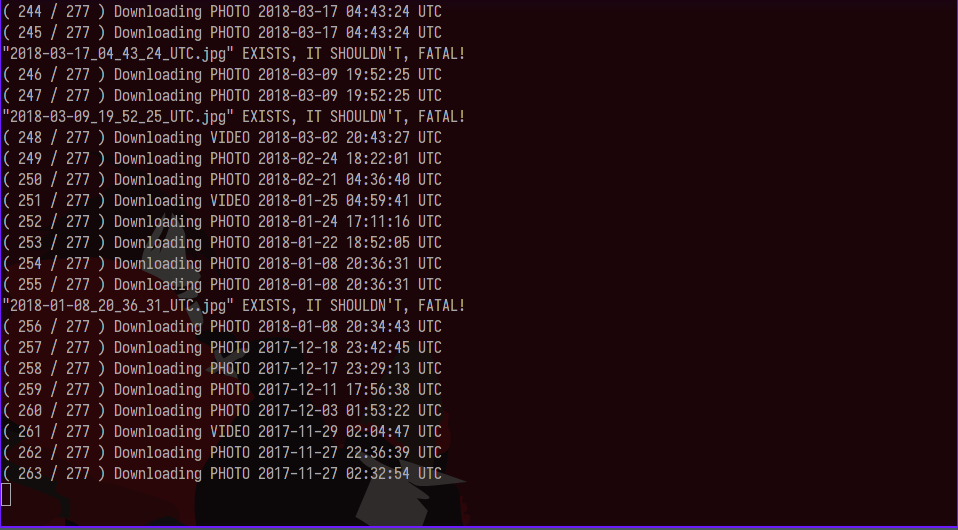
I don’t even know how this happened. There should not be multiple images taken at the same exact second, it’s not like I can be in two places at once. Also my script didn’t stop when it was supposed to :(.
I thought about this for a few moments wondering what I was missing and I came up with an idea that led me to add a new addition to the script. If you’ve ever used snapchat you know that videos are split up into multiple segments if they are longer than 10 seconds or so. This made me wonder whether or not snapchat was tagging all the parts of a multi-part video with the same timestamp. This is the exact reason I implemented duplicate detection, if I hadn’t I would have overwrote and deleted some of my videos, not good.
To verify that there is actually multiple photos with the same timestamp and there isn’t just something wrong with my script, I made another quick script to test:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#!/usr/bin/env python
import argparse
import json
import sys
parser = argparse.ArgumentParser()
parser.add_argument("jsonfile")
args = parser.parse_args()
jsonObj = None
with open(args.jsonfile, "r") as handle:
jsonObj = handle.read()
if not jsonObj:
print("Failed to read")
sys.exit(1)
obj = json.loads(jsonObj)
dates = [x['Date'] for x in obj['Saved Media']]
origLength = len(dates)
dates_restrict = set(dates)
setLength = len(dates_restrict)
print(origLength)
print(setLength)
Again, not efficient or pretty but right now I’m interested in speed of implementation and this is the easiest shortest thing I thought to write. All we do is get a list of dates using a list comprehension ( I love python :D ), create a set from our list, and then print the lengths of the original list and the set.
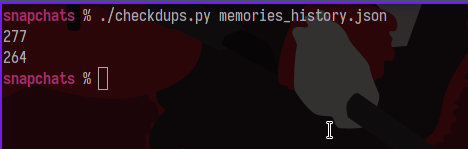
Yepp our set is shorter, so there’s a few duplicates. At least we know for sure now. There’s a few ways we could handle this but this situation made me think of what a web browser or file manager does when you try to save a duplicate file. Usually these programs will put a number near the end of the filename denoting it’s version, so let’s just do that to keep it simple
Getting results
We’ve done most of the work already so this isn’t hard to add to our script:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def downloadItem(item):
resp = requests.post(item['Download Link'])
if resp.status_code != 200:
print("PHANTOM LINK STATUS: " + str(resp.status_code))
return False
if not resp.text:
print("PHANTOM LINK EMPTY")
return False
imgDownload = requests.get(resp.text)
if imgDownload.status_code != 200:
print("IMG DOWNLOAD STATUS: " + str(imgDownload.status_code))
return False
if len(imgDownload.content) < 1:
print("IMG DOWNLOAD CONTENT EMPTY")
return False
downloadName = generateSerializedDT(item['Date'])
ext = ".mp4"
if item['Media Type'] == "PHOTO":
ext = ".jpg"
newName = downloadName + ext
counter = 1
while exists(newName): # <--- CHANGE HERE
newName = downloadName + "_" + str(counter) + ext
counter = counter + 1
print(newName + " Exists, trying: " + newName)
with open(newName, "w+b") as handle:
handle.write(imgDownload.content)
return True
I’ve changed the if statement checking if our filename exists into a while loop that continuously checks and increments a counter if it does exist. This way no matter how many duplicates there are they will all get saved ( version 1, 2, 3, …, etc).
Another run of our script: 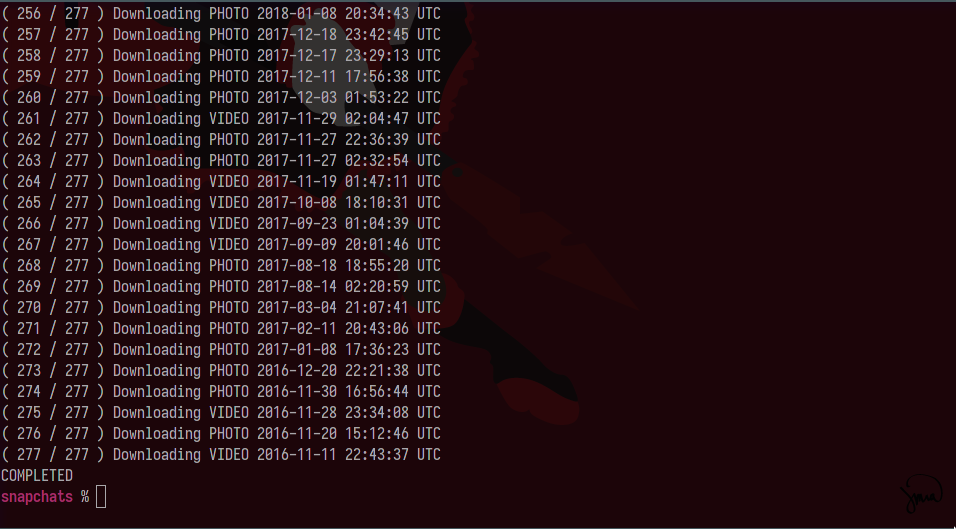
It completed! If we have a look at the execution directory we can see all the downloaded files: 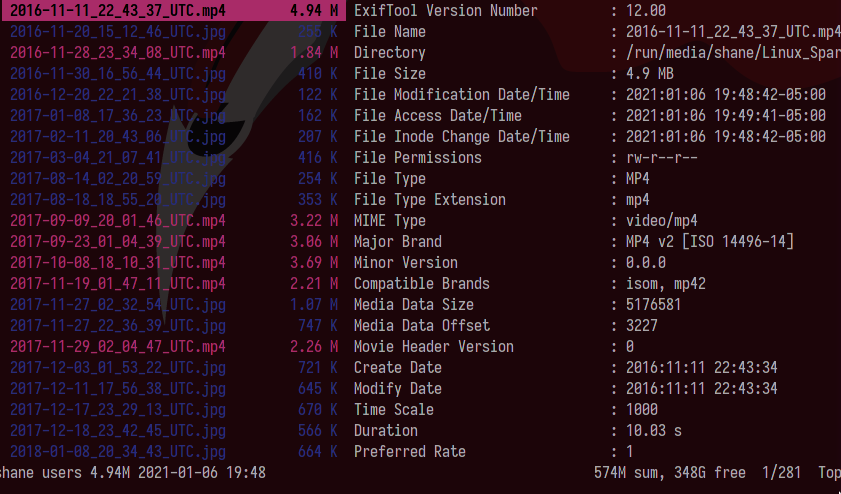
Conclusion
Well this was a nice little exercise for Wednesday night. Lot’s of people who ask me about getting into programming really have it in their head that to do programming you have to make massive projects that do complicated things. You certainly can if you want to and I certainly have some of those, but for me programming is a tool to accomplish a task. Many people are okay doing stuff manually by hand. I could have gone through all of those links and downloaded each video manually in a mind numbing repetition of get link, download, save but by using some simple python knowledge I was able to automate the process. This method also ensured there were no mistakes which could have been made doing the process manually resulting in lost photos. Programming is a great tool even for the general person to improve workflow and productivity. If you approach problem solving from this perspective there’s lots of instances that will allow you to do a better job and save time.
Also it turns out the videos with the duplicate timestamp were actually duplicate videos. Didn’t think snapchat would store memories more than once but it looks like they do in certain instances.
Anyways that’s enough talking for today. Like always here’s the full code if you would like to give it a try yourself:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
#!/usr/bin/env python
#||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
# Author: Shane Brown
# Email: contact at shanebrown dot ca
# Description: Script to download snapchat memories
#||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
import argparse
import json
import sys
import requests
import datetime
from os.path import exists
def generateSerializedDT(dt):
curDt = datetime.datetime.strptime(dt, '%Y-%m-%d %H:%M:%S %Z')
serialized = str(curDt.year) + "-" + str(curDt.month).zfill(2) + "-" + str(curDt.day).zfill(2) + "_" + str(curDt.hour).zfill(2) + "_" + str(curDt.minute).zfill(2) + "_" + str(curDt.second).zfill(2) + "_UTC"
return serialized
def downloadItem(item):
resp = requests.post(item['Download Link'])
if resp.status_code != 200:
print("PHANTOM LINK STATUS: " + str(resp.status_code))
return False
if not resp.text:
print("PHANTOM LINK EMPTY")
return False
imgDownload = requests.get(resp.text)
if imgDownload.status_code != 200:
print("IMG DOWNLOAD STATUS: " + str(imgDownload.status_code))
return False
if len(imgDownload.content) < 1:
print("IMG DOWNLOAD CONTENT EMPTY")
return False
downloadName = generateSerializedDT(item['Date'])
ext = ".mp4"
if item['Media Type'] == "PHOTO":
ext = ".jpg"
newName = downloadName + ext
counter = 1
while exists(newName):
newName = downloadName + "_" + str(counter) + ext
counter = counter + 1
print(newName + " Exists, trying: " + newName)
with open(newName, "w+b") as handle:
handle.write(imgDownload.content)
return True
# BEGIN EXECUTION
parser = argparse.ArgumentParser()
parser.add_argument("jsonfile", help="json file to parse")
args = parser.parse_args()
if not exists(args.jsonfile):
print("Given file does not exist")
sys.exit(1)
jsonObj = None
with open(args.jsonfile, "r") as handle:
jsonObj = handle.read()
if not jsonObj:
print("Failed to read given json file")
sys.exit(1)
obj = json.loads(jsonObj)
lenStr = str(len(obj['Saved Media']))
allGood = True
for index, item in enumerate(obj['Saved Media']):
print("( " + str(index+1) + " / " + lenStr + " ) Downloading " + item['Media Type'] + " " + item['Date'])
if not downloadItem(item):
allGood = False
break
if allGood:
print("COMPLETED")
else:
print("JOB STOPPED BECAUSE OF ERROR")